
This is how a pipe works. Data is copied once into kernel space, and once out of kernel space. There will be two copies of the same data.
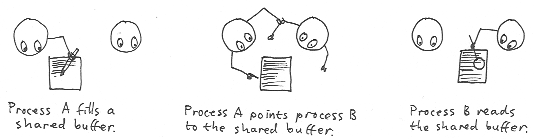
This is how ZZ works. Data is never copied, and there are no duplicates of a buffer.
This is how a pipe works. Data is copied once into kernel space, and once out of kernel space. There will be two copies of the same data.
This is how ZZ works. Data is never copied, and there are no duplicates of a buffer.